


Asia Pacific Academy of Science Pte. Ltd. (APACSCI) specializes in international journal publishing. APACSCI adopts the open access publishing model and provides an important communication bridge for academic groups whose interest fields include engineering, technology, medicine, computer, mathematics, agriculture and forestry, and environment.

 Open Access
Open Access
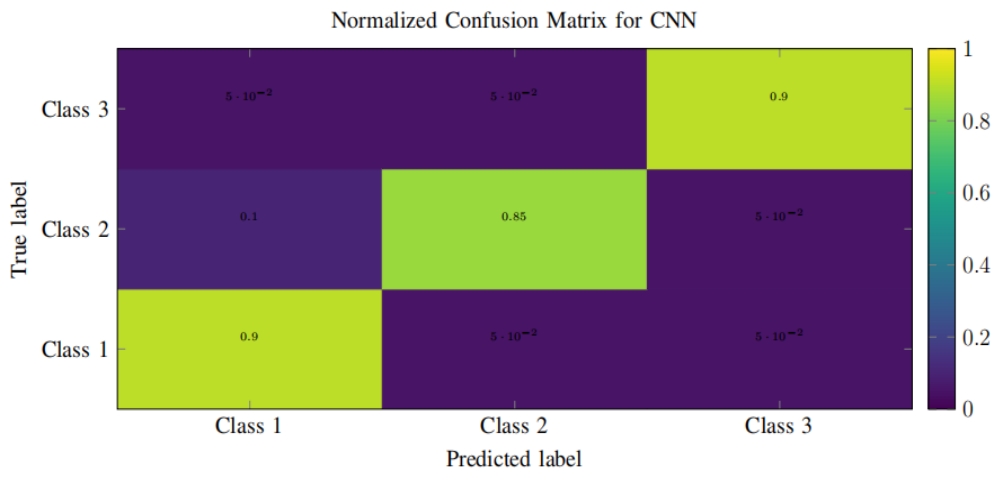
Accurate and efficient brain tumor segmentation is critical for diagnosis, treatment planning, and outcome monitoring in neuro-oncology. This study presents an integrated framework that combines deep learning-based tumor segmentation with 3D spatial reconstruction and metaverse-aligned visualization. The Cellpose segmentation model, known for its shape-aware adaptability, was applied to grayscale T1-weighted MRI slices to generate binary tumor masks. These 2D masks were reconstructed into 3D surface meshes using the marching cubes algorithm, enabling the computation of clinically relevant spatial parameters including centroid, surface area, bounding box dimensions, and mesh extents. The resulting tumor models were embedded into a global coordinate system and visualized across orthogonal planes, simulating extended reality (XR) environments for immersive anatomical exploration. Quantitative evaluation using DICE, Intersection over Union (IoU), and Positive Predictive Value (PPV) validated the segmentation accuracy, with DICE scores exceeding 0.85 in selected cases. The reconstructed tumors exhibited surface areas ranging from ~45,000 to ~74,000 voxel² units and extended across more than 200 units along the Y and Z axes. Although volumetric values were not computed due to open mesh geometry, the spatial profiles provided a reliable foundation for integration into metaverse platforms. This pipeline offers a lightweight and scalable approach for bridging conventional 2D tumor imaging with immersive 3D applications, paving the way for advanced diagnostic, educational, and surgical planning tools.
Open Access
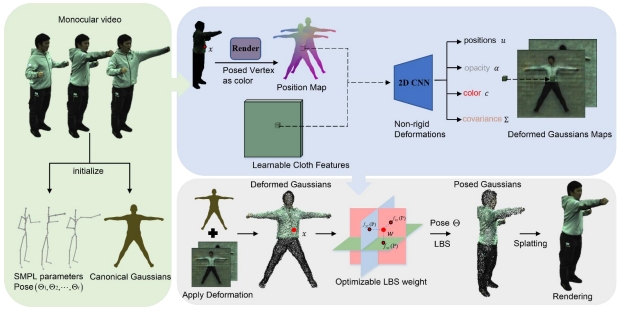
The metaverse, as a shared virtual collective space, holds unparalleled promise for engaging 3D experiences through augmented reality (AR) and virtual reality (VR). Despite notable progress, there still exists a void in the proper visualization of intricate data and environments in real-time. This article suggests a novel approach utilizing AR/VR technologies to enhance 3D visualization in the metaverse. Through the integration of real-time processing of data, multi-layered virtual environments, and advanced rendering methods, the envisioned system increases interaction, immersion, and scalability. The computational model relies on hybrid algorithms that integrate machine learning-based object recognition and GPU-based rendering efficiency. This work introduces a new hybrid method for improving real-time 3D visualization in Metaverse through the integration of machine learning (ML)-based object identification and GPU-based rendering. The system uses the identified importance of objects to dynamically adjust the level of detail (LOD) of individual objects in the scene to optimize rendering quality and computational performance. The major system components are an object recognition module that classifies and ranks objects in real-time and a GPU rendering pipeline that dynamically scales the rendering detail according to the priority of the objects. The algorithm tries to achieve the trade-off between high visual quality and system performance by using deep learning for precise object detection and GPU parallelism for efficient rendering. Experimental outcomes illustrate that the introduced system realizes considerable enhancements in rendering speed, interaction latency, and visual quality compared to common AR/VR rendering methods. The results confirm the prospects of fusing AI and graphics to develop more effective and visually sophisticated virtual environments.
Open Access

Prof. Zhigeng Pan
Professor, Hangzhou International Innovation Institute (H3I), Beihang University, China

Prof. Jianrong Tan
Academician, Chinese Academy of Engineering, China




.jpg)

.jpg)

Conference Time
December 15-18, 2025
Conference Venue
Hong Kong Convention and Exhibition Center (HKCEC)
...
Metaverse Scientist Forum No.3 was successfully held on April 22, 2025, from 19:00 to 20:30 (Beijing Time)...
We received the Scopus notification on April 19th, confirming that the journal has been successfully indexed by Scopus...
We are pleased to announce that we have updated the requirements for manuscript figures in the submission guidelines. Manuscripts submitted after April 15, 2025 are required to strictly adhere to the change. These updates are aimed at ensuring the highest quality of visual content in our publications and enhancing the overall readability and impact of your research. For more details, please find it in sumissions...